从 CPU 到 NPU:架构原理全解析与协同趋势剖析 - 人工智能计算全新趋势详解
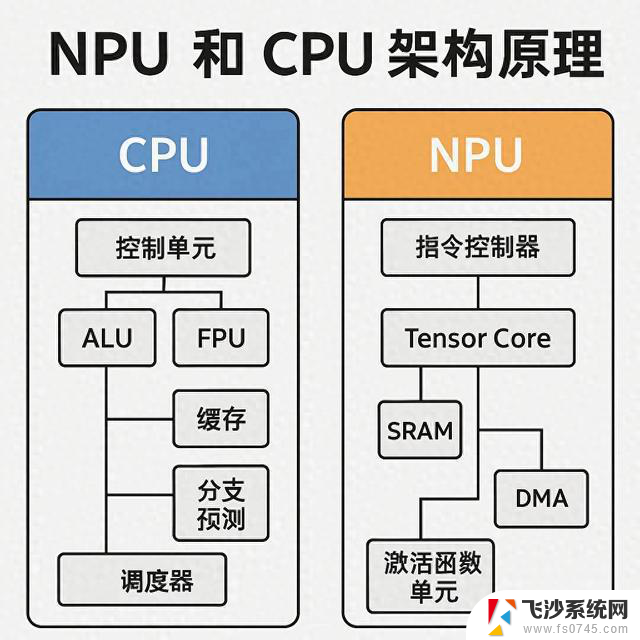
一、什么是 CPU?
CPU(Central Processing Unit)是通用计算架构的核心。它负责通用逻辑运算、流程控制、指令解码与执行。现代 CPU 通常具备以下特征:
CPU 架构关键组件:
模块
作用
ALU(算术逻辑单元)
执行整数加减乘除等
FPU(浮点单元)
执行浮点运算
寄存器组
快速读写数据
L1/L2/L3 Cache
缓存层级,提高访存效率
分支预测单元
减少流水线停顿
调度器
将微指令分发到执行单元
MMU
地址映射与权限控制
CPU 优势:通用、灵活、支持系统层级复杂任务
CPU 弱点:面临 AI 算法中矩阵乘法、大规模并行时计算密度低、能效差
二、什么是 NPU?
NPU(Neural Processing Unit,神经网络处理器)是专门为深度学习计算任务加速而设计的专用处理器。也称作 DLA(Deep Learning Accelerator)、AI Engine、TPU(Google)。
NPU 的典型特性:
NPU 架构构成(以典型 AI SoC 为例):
模块
作用
Tensor Core / MAC阵列
执行矩阵乘法、卷积核滑动
SRAM/On-Chip Buffer
存放中间结果,减少 DRAM 访问
DMA/指令控制器
从主存中搬运参数与输入
激活函数单元(ReLU/Softmax)
专门实现神经网络激活操作
NPU Driver & Compiler
接收模型,调度计算图到指令
NPU 优势:吞吐量高、功耗低、单位面积性能高(TOPS/W)
NPU 局限:通用性差,需 AI 框架支持编译部署,难以处理控制密集型逻辑
三、对比分析:CPU vs NPU 架构核心差异
项目
CPU
NPU
指令类型
通用计算指令(加减跳转等)
专用 AI 运算指令(MatMul/Conv)
架构
超标量、乱序、缓存层丰富
并行张量阵列,流水数据驱动
精度
通常为 FP64/FP32
支持低精度 INT8/FP16/混合精度
数据调度
面向程序流(control-flow)
面向数据流(dataflow)
软件生态
通用 OS / 多语言支持
框架绑定,如 TensorFlow、ONNX、Tengine
应用场景
操作系统、浏览器、IDE、逻辑控制
推理(Inference)、图像识别、语音识别
能效
每 TOPS/W < 1
可达 10~100 TOPS/W(高效)
四、NPU 架构演进趋势
1.
从固定功能 → 可编程
2.
从单芯片 → 多芯异构协同
3.
支持混合精度与稀疏计算
4.
系统软件栈完善
五、CPU 与 NPU 的协同计算模型(真实应用案例)
场景:智能摄像头(IPC)AI 边缘推理
场景:手机 AI 拍照
六、未来趋势:统一架构与软件驱动
趋势
说明
CPU + NPU + GPU 融合架构(SoC)
高通、苹果、华为等均采用统一内存访问的异构处理架构
统一 AI 编译中间件(如 ONNX-RT、TensorRT)
开发者只需部署模型,中间件自动选择最优执行单元
AI 原生操作系统调度支持
嵌入式 RTOS/Linux 开始集成 AI 调度器,动态将 AI 任务 offload 到 NPU
开源 IP 核与 RISC-V NPU 发展
包括 Alibaba T-Head、SiFive、Google RISC-V TPU 研究中
七、总结
结论
说明
CPU 与 NPU 是互补关系
通用任务靠 CPU,AI 密集运算靠 NPU
NPU 在边缘 AI 场景中越来越不可或缺
能效高,推理快,延迟低
软件与硬件协同是发展核心
编译器、运行时、模型格式将决定 NPU 落地效率
学习 NPU 架构是未来工程师的核心技能之一
尤其在边缘计算、IoT、车载、智能终端等场景
从 CPU 到 NPU:架构原理全解析与协同趋势剖析 - 人工智能计算全新趋势详解相关教程
-
 CPU的指令系统又称为什么?深入解析其名称与功能-解密计算机指令集架构
CPU的指令系统又称为什么?深入解析其名称与功能-解密计算机指令集架构2024-11-08
-
 计算机的构造和原理之CPU介绍:深入了解中央处理器的工作原理
计算机的构造和原理之CPU介绍:深入了解中央处理器的工作原理2023-12-19
-
 微软发布关于网络犯罪、国家背景网络行动的新报告,揭示全球威胁的最新趋势
微软发布关于网络犯罪、国家背景网络行动的新报告,揭示全球威胁的最新趋势2023-10-07
-

- 微软全新Xbox Series X游戏主机拆解:6nm芯片和创新散热设计详细解析
- 处理器“三国鼎立”:从CPU、GPU到DPU,解析处理器类型及应用领域
- 显卡的诞生,显卡与GPU,NVIDIA英伟达发展历程全解析
- AMD官方超频工具Ryzen Master 3.0.0.4199版本发布,全面解析新功能和优化
- 搭载全新NVIDIA DRIVE Orin平台,腾势N7秒变老司机,领跑智能驾驶技术!
- 微软CEO称新人工智能个人电脑将重振Windows PC与Mac的竞争
- 如何使用Windows自带命令查询电脑真实信息?
- 2025科隆游戏展开幕华硕显卡引爆玩家狂欢,精彩花絮抢先看
- Windows四十周年:Windows 7如何洗刷Vista的罪孽,重返辉煌
- AMD回应AM5插槽烧毁问题:厂商BIOS配置不当,建议升级解决
- 我的6TB企业硬盘被Win11爆了 教大家如何屏蔽Windows更新,解决Win11更新导致硬盘爆满问题
- 微软紧急修复 Windows 11 2025 年 8 月更新问题
热门推荐
系统资讯推荐
- 1 如何使用Windows自带命令查询电脑真实信息?
- 2 2025科隆游戏展开幕华硕显卡引爆玩家狂欢,精彩花絮抢先看
- 3 Windows四十周年:Windows 7如何洗刷Vista的罪孽,重返辉煌
- 4 Windows 10停更倒计时,10月14日后不再修补,升级至Windows 11还是购买ESU?
- 5 比台式机处理器还强?这颗锐龙神U是真的强,性能如何?
- 6 AMD官宣!11月11日公布下一代产品与技术路线图,重磅揭秘AMD未来发展规划
- 7 Win11/10微软商店更新:用户如何彻底关闭应用自动更新
- 8 白宫:英伟达AMD上缴15%在华收入,或扩大至更多公司措施或将扩大至更多公司
- 9 基于FPGA和CPU的数据采集专利申请,提升数据处理效率
- 10 英伟达与AMD芯片对华出口获批,助推国内AI算法建设,产业链全面受益
win10系统推荐
系统教程推荐
- 1 怎样使电脑不卡顿更流畅win7 电脑卡顿不流畅怎么办
- 2 win11网络中不显示 Windows11 Wi Fi网络不显示怎么解决
- 3 电脑怎么打印机连接打印机 电脑连接打印机的步骤详解
- 4 excel汇总表怎么取分表数据 Excel 如何合并多个分表数据到总表
- 5 输入法 顿号 win10默认输入法怎么打顿号符号
- 6 笔记本没有鼠标箭头怎么办 电脑鼠标箭头消失了怎么回事
- 7 笔记本连接wifi但是不能上网 笔记本连接无线网络但无法打开网页怎么办
- 8 win11如何创建word文件 Word文档创建步骤
- 9 戴尔截屏快捷键 戴尔笔记本电脑截图快捷键是什么
- 10 电脑切换打字键在哪里 Win10输入法怎么关闭